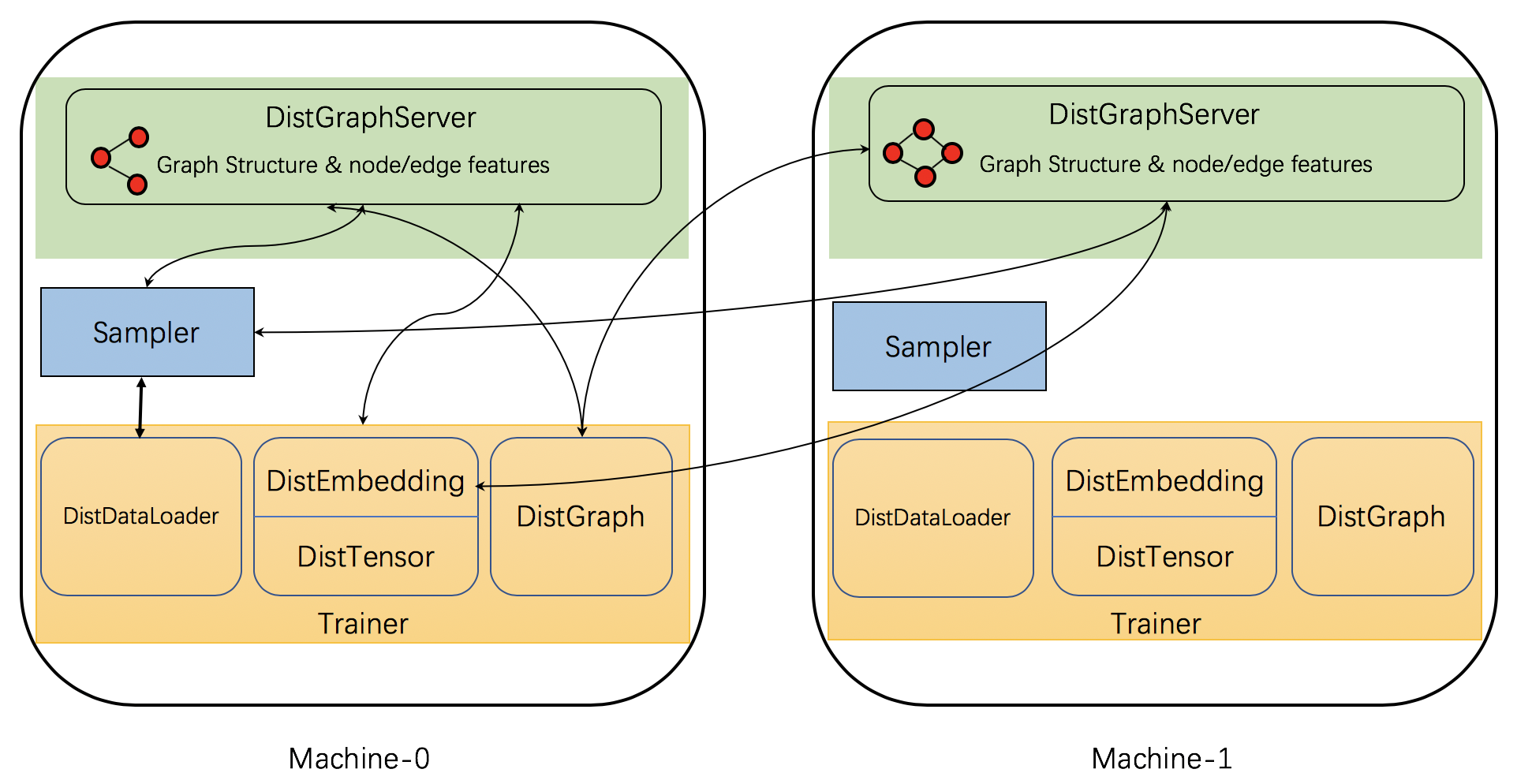
DGL
Distributed
import dgl
import torch as th
dgl.distributed.initialize('ip_config.txt')
th.distributed.init_process_group(backend='gloo')
g = dgl.distributed.DistGraph('graph_name', 'part_config.json')
pb = g.get_partition_book()
train_nid = dgl.distributed.node_split(g.ndata['train_mask'], pb, force_even=True)
# Create sampler
sampler = NeighborSampler(g, [10,25],
dgl.distributed.sample_neighbors,
device)
dataloader = DistDataLoader(
dataset=train_nid.numpy(),
batch_size=batch_size,
collate_fn=sampler.sample_blocks,
shuffle=True,
drop_last=False)
# Define model and optimizer
model = SAGE(in_feats, num_hidden, n_classes, num_layers, F.relu, dropout)
model = th.nn.parallel.DistributedDataParallel(model)
loss_fcn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=args.lr)
# training loop
for epoch in range(args.num_epochs):
with model.join():
for step, blocks in enumerate(dataloader):
batch_inputs, batch_labels = load_subtensor(g, blocks[0].srcdata[dgl.NID],
blocks[-1].dstdata[dgl.NID])
batch_pred = model(blocks, batch_inputs)
loss = loss_fcn(batch_pred, batch_labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()